Machine Learning-based Gaze Correction
D. Kononenko and V. Lempitsky. Learning To Look Up: Realtime Monocular Gaze Correction Using Machine Learning, IEEE Computer Vision and Pattern Recognition (CVPR), Boston MA, 2015 PDF
A follow-up paper on applying deep neural networks for gaze correction could be found on the DeepWarp page.
D. Kononenko, Y. Ganin, D. Sungatullina, and V. Lempitsky. Photorealistic Monocular Gaze Redirection Using Machine Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2017.
General description
The problem of gaze in videoconferencing has been attracting researchers and engineers for a long time. The problem manifests itself as the inability of the people engaged into a videoconferencing (the proverbial “Alice” and “Bob”) to maintain gaze contact. The lack of gaze contact is due to the disparity between Bob’s camera and the image of Alice’s face on Bob’s screen (and vice versa).
We revisit the problem of gaze correction and present a solution based on supervised machine learning. At training time, our system observes pairs of images, where each pair contains the face of the same person with a fixed angular difference in gaze direction. It then learns to synthesize the second image of a pair from the first one. After learning, the system becomes able to redirect the gaze of a previously unseen person by the same angular difference (10 or 15 degrees upwards in our experiments). Unlike many previous solutions to gaze problem in videoconferencing, ours is purely monocular, i.e. it does not require any hardware apart from an in-built web-camera of a laptop. Being based on efficient machine learning predictors such as decision forests, the system is fast (runs in real-time on a single core of a modern laptop).
In the paper, we demonstrate results on a variety of videoconferencing frames and evaluate the method quantitatively on the hold-out set of registered images. The supplementary video at the project website shows example sessions of our system at work.
Unlike most previous methods, we do not attempt to synthesize a view for a virtual camera. Instead, our method emulates the change in the appearance resulting from a person changing her/his gaze direction by a certain angle (e.g. ten degrees upwards), while keeping the head pose unchanged.
Below, for an example from the Columbia Gaze Dataset, we show the input (left), the actual image with the gaze direction 10 degrees higher (middle), and the analogous change in gaze direction simulated in real-time using our method (right):



Method overview
We use an off-the-shelf real-time face alignment library to localize facial feature points. For each eye, we compute a tight axis-aligned bounding box. At test time, for every pixel (x,y) in the bounding box we determine a 2D eye flow vector. The pixel value at (x,y) is then “copy-pasted” from another location determined by using the eye flow vector as an offset.
The main variant of our system determine the appropriate eye flow vector using a special kind of randomized decision tree ensembles.
The vector is determined based on the appearance of the patch surrounding the pixel, and the location of the pixel w.r.t. the feature points.
In more detail, a pixel is passed through a set of specially-trained ensemble of randomized decision trees (eye flow trees). Two kinds of tests are are applied to pixel: an appearance test and a location test. An appearance test compares the difference of two pixel values in some color channel with the threshold. A location test compares distance to some of the feature points in one of two dimensions with the threshold. To handle scale variations, we rescale the training images to the same size, and we rescale the offsets in the tree tests and the obtained eye flow vectors by an appropriate ratio at test time.
In an eye flow tree, each leaf stores the map of compatibilities between the set of training examples and each possible offset (eye flow vector). We then sum together the compatibility maps from several trees, and pick the eye flow vector that minimizes the aggregated map:
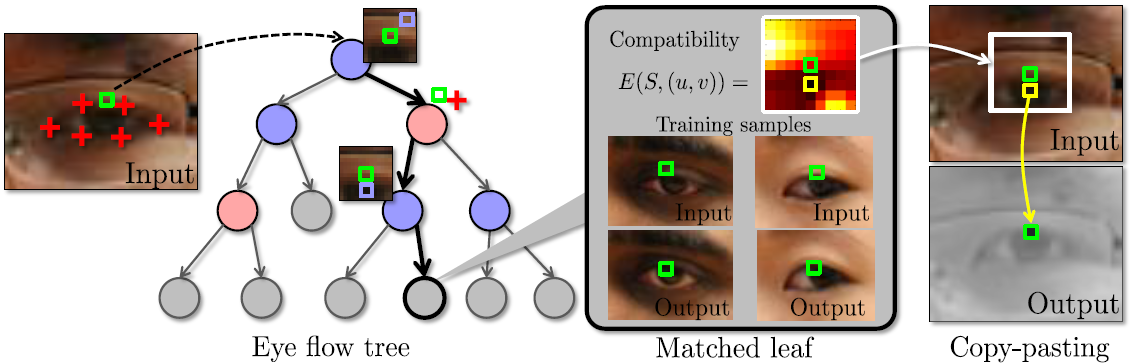
At learning phase, we assume that a set of training image pairs is given. We assume that within each pair the images correspond to the same head pose of the same person, same imaging conditions, etc., and differ only in the gaze direction. We also rescale all pairs based on the characteristic radius of the eye in the input image. Eye flow trees are trained in a weakly-supervised manner, as each training sample does not include the target vectors. The goal of the training is to build a tree that splits the space of training examples into regions, so that for each region replacement with the same eye flow vector produces good result for all training samples that fall into that region.
We also investigate gaze redirection based on an image-independent flow field — a simple variant of our system, where each eye flow vector is independent on the test image content and is based solely on the relative position in the estimated bounding box. So, in the learning phase we consider all training examples for a given location (x,y) and find the offset minimizing the compatibility score.
Results
Below, are some results (on hold-out images) for our method. Each pair, shows a cutout from the input frame and the output of our method on the right:

The top two rows shows redirection by 10 degrees, and the bottom layer shows redirection by 15 degrees.
Video
RU Patent 2596062, August 8, 2016.