Deep billion-scale indexing
Efficient Indexing of Billion-Scale datasets of deep descriptors
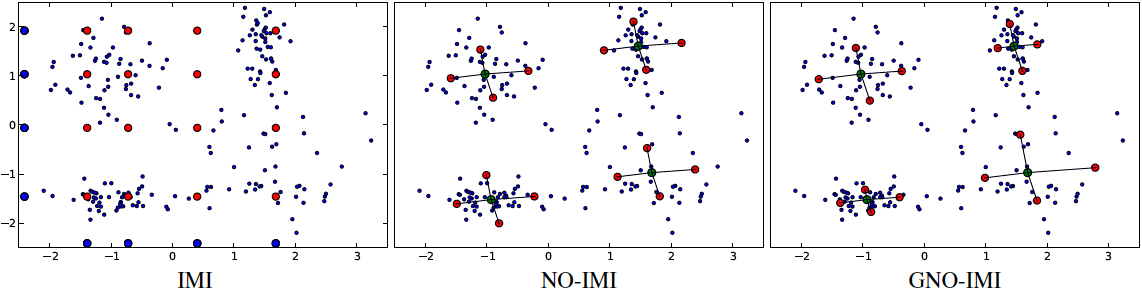
In this project we investigated the indexing strategies for billion-scale datasets of deep descriptors, extracted from the last layers of convolutional neural networks. We have introduced two indexing structures: the Non-Orthogonal Inverted Multi-Index (NO-IMI) and the Generalized Non-Orthogonal Inverted Multi-Index. These structures continue the idea of the standard inverted multi-index but do not decompose the search space into orthogonal subspaces. We have demonstrated the success of the (G)NO-IMI on a new billion-scale dataset of deep descriptors (DEEP1B).
Paper: Artem Babenko and Victor Lempitsky, Efficient Indexing of Billion-Scale datasets of deep descriptors, CVPR 2016
Code: https://github.com/arbabenko/GNOIMI
Dataset: https://yadi.sk/d/11eDCm7Dsn9GA
The dataset contains:
- One billion 96-descriptors in the base set. The vectors are stored in .fvecs format. The base file is splitted into several chunks no bigger than 10Gb and one has to concatenate the chunks to obtain the file.
- About 350 millions vectors in the learn set. This set is also stored in .fvecs format and is splitted into several chunks.
- 10.000 queries
- The precomputed exact nearest neighbors ids for the queries. The ids are stored in .ivecs format.
- The sample dataset containing 10 millions descriptors.