Learnable Visual Markers
Oleg Grinchuk, Vadim Lebedev, Victor Lempitsky
To appear at NIPS2016 (arxiv preprint)
Abstract
We propose a new approach to designing visual markers (analogous to QR-codes, markers for augmented reality, and robotic fiducial tags) based on the advances in deep generative networks. In our approach, the markers are obtained as color images synthesized by a deep network from input bit strings, whereas another deep network is trained to recover the bit strings back from the photos of these markers. The two networks are trained simultaneously in a joint backpropagation process that takes characteristic photometric and geometric distortions associated with marker fabrication and marker scanning into account. Additionally, a stylization loss based on statistics of activations in a pretrained classification network can be inserted into the learning in order to shift the marker appearance towards some texture prototype. In the experiments, we demonstrate that the markers obtained using our approach are capable of retaining bit strings that are long enough to be practical. The ability to automatically adapt markers according to the usage scenario and the desired capacity as well as the ability to combine information encoding with artistic stylization are the unique properties of our approach. As a byproduct, our approach provides an insight on the structure of patterns that are most suitable for recognition by ConvNets and on their ability to distinguish composite patterns.
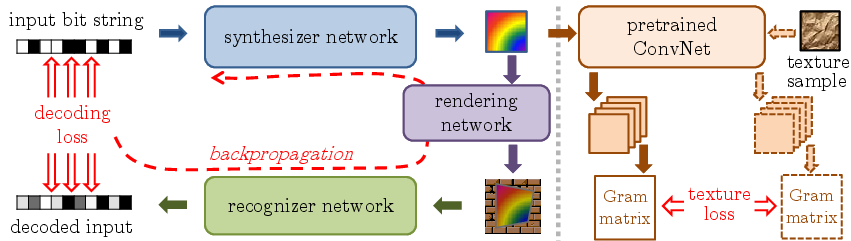
Architecture
The outline of our approach and the joint learning process. Our core architecture consists of the synthesizer network that converts input bit sequences into visual markers, the rendering network that simulates photometric and geometric distortions associated with marker printing and capturing, and the recognizer network that is designed to recover the input bit sequence from the distorted markers. The whole architecture is trained end-to-end by backpropagation, after which the synthesizer network can be used to generate markers, and the recognizer network to recover the information from the markers placed in the environment. Additionally, we can enforce the visual similarity of markers to a given texture sample using the mismatch in deep Gram matrix statistics in a pretrained network as the second loss term during learning (right part):
The visualization of our rendering network. For the input marker M on the left the output of the network is obtained through several stages, which are all piecewise-differentiable w.r.t. inputs. The use of piecewise-differentiable transforms allows us to backpropagate through the rendering network:

Examples of textured 64-bit markers. Texture prototype is shown on the right:

NB: in the paper we use “-1″ instead of “0” when discussing bit encodings.
The picture below demonstrates the user interface of our marker recognizer. The number of correctly recognized bits, the retrieved bit sequence and the elapsed time in milliseconds are shown on the screen. The black square represents the area where recognizer network expects to see the marker. For the correct code recovery, the marker and black square have to be aligned.
As affine transformations were included in our training process, the code recovery has some robustness to imperfect alignment. The robustness to geometric transforms can be enhanced by adding a separate localization step.

Click on the image to start the animation
As shown below, our markers are surprisingly robust to occlusion, despite the fact that occlusion was not modeled during the training process (eventhough this could have been possible). Apparently, even without occlusion modeling, the systems learns to use very distributed representations for bits of input codes:

Click on the image to start the animation
The distributed representations of bits are also visible in the animations below, where a single bit is changed between adjacent frames, as the encoded bit sequences change from all-zeros to all-ones and back. Switching a single bit usually incurs slight changes of appearance over multiple locations in a marker: